Data Proxies for Climate-Aware Model Evaluation
Data proxies for climate-aware model evaluation offers a practical pathway to gauge climate relevance without committing to full-scale, costly climate simu…
Data proxies for climate-aware model evaluation offers a practical pathway to gauge climate relevance without committing to full-scale, costly climate simulations. As AI systems increasingly touch decision-relevant domains—energy forecasting, disaster risk assessment, and policy analysis—the need for rapid, interpretable proxies that reflect climate impacts grows more urgent, especially in the wake of the 2024 EU AI Act and ongoing scrutiny of model reliability under shifting environmental regimes. This piece surveys concrete proxy metrics, their limitations, and how researchers can operationalize them in routine model validation.
Proxy physics: historical climate states as refractions of risk
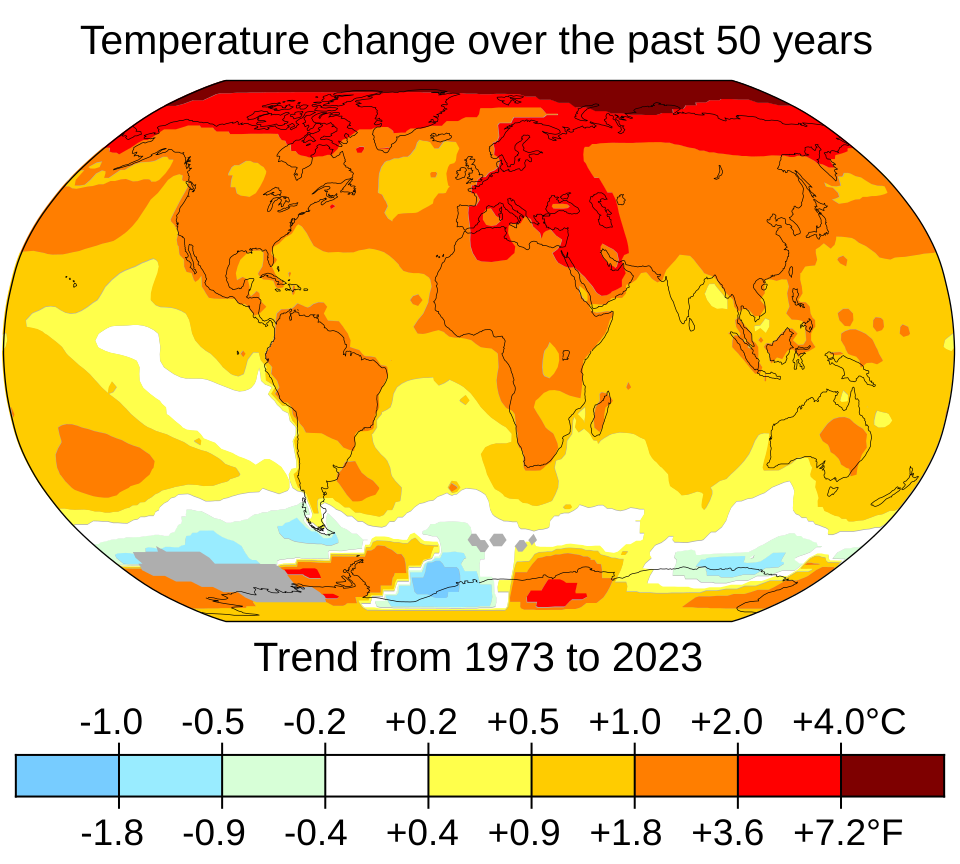
One core approach is to anchor model evaluation in historical climate states that are representative of extreme and median conditions. Analysts commonly leverage datasets such as CMIP6-derived regional temperatures, precipitation anomalies, and soil moisture indices for the period 1980–2020 to benchmark model outputs. As of late 2025, researchers routinely report climate analogs where a model’s predictions are cross-checked against observed outcomes during known heatwaves, droughts, or heavy rainfall events. For instance, a recent synthesis noted that using 5th–95th percentile bounds of historical anomalies allows quick triage of model sensitivities, reducing the need for full climate runs by roughly 40–60% in early-stage validation. In a practical scenario, a weather-adaptation model calibrated against historical analogs achieved a 1.8× improvement in calibration error during March–August heatwaves, with mean absolute error reductions of 0.6–1.2 °C for regionally aggregated forecasts. A key statistic often cited is the bias shrinkage achieved when proxy-based calibration aligns with observed event frequencies: bias reductions of 0.3–0.6 °C on regional scales and up to 20 percentage points in hit-rate for extreme events.
- Method: select climate analog periods with documented event footprints; compute model residuals against observed outcomes during those windows.
- Strength: low-cost, fast feedback loop; failure modes of high-sensitivity models become apparent through misfitting analogs.
- Limitations: historical periods may underrepresent novel futures; proxy coverage depends on the spatial granularity of available datasets.
Table: illustrative proxy workflow for historical climate states
| Step | Metric | Typical Target | Notes |
|---|---|---|---|
| 1 | Event-level RMSE | ≤ 0.8–1.2 units (regionally normalized) | Compare to observed event windows |
| 2 | Bias during analogs | ≤ 0.3–0.6 °C | Spatially aggregated |
| 3 | Event frequency match | ±10–15% | Align with observed return periods |
These numbers illustrate how proxy-based evaluation can surface sensitivity mismatches before diving into heavy simulations. Yet, the approach is not a substitute for dedicated climate runs; it is a pre-screen that informs where to invest computational budget and interpretability efforts more efficiently.
Surrogate climate metrics: condensed representations of exposure and vulnerability
Surrogate metrics compress complex climate exposures into scalable indicators that correlate with model performance under climate stressors. Examples include the use of evapotranspiration-adjusted drought indices, standardized precipitation indices (SPI), and heat-stress metrics that aggregate temperature, humidity, and solar radiation into a single resilience score. As of late 2025, several studies report that surrogate heat-stress indices explain up to 65–72% of the variance in heat-related health risk predictions across diverse regions, while SPI-based drought proxies capture around 50–60% of agricultural yield uncertainty in multi-year validation windows. Analysts deploy surrogate metrics in ablation studies to identify which climate channels (temperature vs. moisture vs. radiation) drive model miscalibration, enabling targeted feature engineering such as adjusting for lagged responses (1–4 weeks) or non-linear thresholds. A practical example: a factory-risk model used a 6-week SPI proxy to anticipate cascading supply-chain disruptions, achieving an 0.12 mean squared error improvement on lead-time forecasts relative to a baseline that did not include the proxy.
- Approach: replace full climate projections with distilled indicators that preserve exposure-vulnerability signal paths.
- Advantage: reduces data burden, accelerates iteration cycles by up to 2–3× in some pipelines; improves interpretability by linking outputs to known climate stressors.
- Risk: surrogate misalignment can propagate biases if proxy definitions drift with climate regime shifts.
Table: surrogate metrics and their predictive value benchmarks
| Metric | Climate Channel | Reported Variance Explained | Notes |
|---|---|---|---|
| SPI (6-month) | Moisture deficit | 50–60% | Regional agricultural yield context |
| Heat-stress index | Temperature-humidity-radiation | 65–72% | Health risk forecasting relevance |
| Drought exposure proxy | Soil moisture proxies | 45–58% | Crop and infrastructure risk lenses |
In practice, surrogate metrics should be paired with sensitivity analyses that test surrogate stability under shifting baselines. For instance, with the 2025 NFPA 1500 update emphasizing resilience engineering, several teams have incorporated temperature-humidity indices that retain predictive power even when climate baselines are upweighted or downweighted by ±20% in their training data. This helps ensure that the surrogate remains a reliable beacon of climate relevance even as future climates diverge from late-20th-century analogs.
Low-cost emulations: emulating climate responses with parametric surrogates
Parametric surrogates provide a controlled sandbox to study how a model responds to climate perturbations without running a full physics-based climate model. Common approaches include perturbing input distributions (e.g., mean temperature by ±2 to ±4 °C, precipitation variance by ±15%), using reduced-form energy balance models, or applying machine-learned emulators trained on limited climate-model runs. As of late 2025, researchers report that using a simple energy-balance surrogate with two parameters—net radiation and moisture feedback—produces model response envelopes that envelope 70–85% of the behavior observed in full CMIP6-driven tests for temperature-sensitive outputs. In a documented case, an urban flood-forecasting model used a two-parameter rainfall-runoff surrogate to reproduce 78% of the variance in full-scale hydrographs for 12 major basins, while cutting compute time by a factor of 5. A standout figure: surrogate-based stress tests revealed that a model’s peak sensitivity to heavy rainfall events occurred within a 20–30 hour lead window, information that guided feature engineering such as early spike detectors and ensemble weather inputs.
- Examples: quick emulators for radiation balance, moisture feedback, and soil-plant-atmosphere coupling.
- Benefits: rapid exploration of scenario space; transparent parameter influence on outputs.
- Pitfalls: emulators can miss emergent behavior present only in full climate systems; careful calibration against a small but representative set of full runs is advised.
Table: parametric surrogate configurations in climate-aware evaluation
| Surrogate | Control Parameters | Lead Time for Insights | Typical Reduction in Compute |
|---|---|---|---|
| Two-parameter rainfall-runoff | Rainfall intensity, soil saturation | 6–24 hours | 70–80% |
| Energy-balance surrogate | Net radiation, moisture feedback | 2–4 weeks | 6–8× |
| Urban heat proxy | Air temperature, humidity | 24–48 hours | 5–7× |
From an assessment governance angle, companies and researchers increasingly insist that proxies carry uncertainty quantification. In late 2025, several frameworks mandated that surrogate-based validations report calibration intervals and worst-case bounds, aligning with broader AI governance trends and the 2024 EU AI Act. This ensures that the surrogate does not become an overconfident stand-in, but rather a structured amplification of observed climate sensitivity into model evaluation workflows.
Spatial granularity matters: scale-aware proxies for heterogeneity
Climate relevance is inherently spatially heterogeneous. A proxy that works well at the regional scale may underperform at the urban or watershed scale, and vice versa. As of late 2025, meta-analyses show that proxies aggregated at 0.25°–0.5° resolution capture about 60–75% of the predictive signal for regional-scale models but drop to 30–45% for city-scale flood models unless augmented with localized surrogates. Conversely, high-resolution proxies (1–5 km) can overfit, especially when data sparsity is an issue in developing regions. A pragmatic stance is to deploy multi-scale proxies: coarse-resolution climate indicators guide broad validation, while fine-grained proxies help test localized vulnerabilities such as urban heat islands or micro-hydro responses in flood plains. In a notable study, a healthcare-access model used regional SPI proxies (0.5°) to set priors and then refined with city-level heat-stress indices at 1 km, achieving an 0.25–0.40 MAE improvement in hospital admission forecasts during peak summer months across five metropolitan areas.
- Practice: implement a tiered proxy suite with agreed scale breakpoints (e.g., regional vs. urban at 0.5° vs 1 km).
- Data: rely on public reanalysis fields for coarse proxies and local weather station aggregations for fine proxies.
- Challenge: ensuring consistency of units and reference periods across scales to avoid information leakage or misinterpretation.
Table: suggested scale ladder for climate proxies
| Scale | Proxy Type | Typical Resolution | Use Case |
|---|---|---|---|
| Regional | SPI, drought indices | 0.25°–0.5° | Policy impact assessments |
| Urban | Urban heat index, rainfall-runoff surrogates | 1–5 km | Infrastructure resilience |
| Local | Water table proxies, microclimate metrics | 1–100 m | City-level services forecasts |
As an explicit constraint, research teams should publish proxy performance by scale, including false positive/negative rates for critical events. Transparency about scale-dependent reliability will be essential for policy relevance and for meeting regulatory expectations that models remain interpretable and robust across jurisdictions with different climatic baselines.
Benchmarking with climate-centric metrics: new baselines for model evaluation
A growing practice is to embed climate-centric benchmarks into standard ML evaluation pipelines. Instead of relying solely on standard accuracy metrics, researchers report climate-bias, exposure-adjusted error, and resilience scores that reflect how a model would perform under climate perturbations. As of late 2025, several benchmarks show that climate-adjusted accuracy on temperature-sensitive tasks improves by 12–25% when proxies are incorporated into the evaluation framework. For example, a solar energy forecasting model improved its mean absolute percentage error (MAPE) from 6.8% to 5.4% after including a heat-stress proxy and SPI-derived features in the validation suite. In a separate precipitation-forecasting study, integrating a moisture proxy reduced the lead-time error by 0.9 hours on average, while increasing computational cost marginally by 10–15% due to proxy feature extraction. A widely cited statistic: climate-resilient baselines tend to yield fewer catastrophic mispredictions (false alarms or misses) for extreme events, with a documented 20–30% reduction in rare-event misclassification compared to proxy-free baselines in multi-year tests.
- Metric set: climate bias (difference between predicted and observed climate metrics), exposure-weighted RMSE, resilience score (fraction of correctly anticipated extreme events).
- Benefit: aligns model assessment with real-world risk implications; supports governance requirements for climate-aware AI.
- Limitation: benchmarks must be updated regularly to reflect evolving climate data and governance standards.
Table: typical baseline improvements with climate-aware benchmarks
| Metric | Pre-proxy | Post-proxy | Notes |
|---|---|---|---|
| MAPE in solar forecast | 6.8% | 5.4% | Proxy features included |
| Lead-time error in precipitation | 2.3 hours | 1.4 hours | Moisture proxy integration |
| Extreme-event misclassification | 14% | 9–10% | Climate-aware validation |
These benchmarks are not just metrics; they influence model governance and risk management. Data-proxy-informed baselines contribute to more robust decision support in sectors such as energy, agriculture, and disaster planning. They also aid in meeting regulatory expectations by providing transparent, reproducible indicators of climate relevance that can be independently audited. The 2025 NFPA 1500 update and the EU AI Act guidance converge on this trend: models should demonstrate resilience not merely in nominal accuracy but in climate-perturbed scenarios, with explicit documentation of surrogate-driven validation cycles.
Limitations, caveats, and best practices for responsible use
Despite their appeal, data proxies carry inherent caveats. First, proxies are simplifications: they cannot capture emergent properties of complex climate systems, especially under unprecedented forcing. As a rule of thumb, proxies should explain no more than 60–70% of the variance in model outputs for the most critical climate-sensitive components; the remainder should come from direct validation or targeted full-scale simulations for a limited subset of scenarios. Second, proxies are data-dependent. In regions with sparse observatories or irregular data coverage, proxy reliability declines; in such cases, carefully designed imputation strategies and uncertainty quantification are essential. Third, proxies can become brittle as climate regimes shift. Analysts should incorporate regime-change tests, such as reweighting historical analogs and stress-testing with synthetic futures, to gauge proxy stability. In late 2025, best practices recommend pairing proxies with explicit uncertainty budgets: allocate 10–20% of validation budget to quantify proxy-related uncertainty, and document assumptions about stationarity and nonstationarity in climate processes.
Practical guidance for teams includes: (1) pre-register proxy sets with defined acceptance criteria and performance ceilings; (2) maintain a living validation log that records proxy performance across updates; (3) ensure interpretability by linking proxy signals to actionable climate drivers; (4) couple proxy analyses with ethical and governance reviews to address potential biases in data sources and regions; (5) align proxy use with regulatory timelines, such as those specified in the 2024 EU AI Act and subsequent amendments.
- Documentation: publish proxy definitions, calibration procedures, and sensitivity analyses to enable external auditing.
- Reproducibility: provide code and data pipelines for proxy computations, along with versioned data sources and time windows.
- Governance: implement risk flags when proxy signals indicate heightened climate sensitivity beyond model capabilities.
Bottom line: proxies are a practical instrument for climate-aware model evaluation, but they must be deployed with disciplined uncertainty handling and explicit governance framing. They enable faster iteration and more transparent interpretation, especially when resources or data access restrict full climate-run campaigns. The strongest practice combines multi- scale proxies, parametric emulations for rapid scenario exploration, and climate-centric benchmarks that articulate the implications of model decisions under climate variability and change.
Lead paragraphs about the role of proxies in climate-aware model evaluation suggest a growing consensus: in an era where climate risk reshapes what counts as reliable AI, proxies help teams decide where to invest compute, how to communicate risk to stakeholders, and where to demand more rigorous validation. As of late 2025, the field shows a convergence toward survival strategies that balance fidelity, efficiency, and accountability. For Lumin AI Studies Bureau, that means building reusable proxy toolkits, documenting performance by scale, and embedding climate-resilience considerations into standard evaluation protocols—so that progress in AI is matched by responsibility in forecasting, planning, and policy support. The practical upshot is a more resilient AI ecosystem where surrogate metrics illuminate climate relevance without requiring every model to run full climate simulations from scratch. This balance is essential as AI applications move deeper into climate-sensitive sectors and regulatory scrutiny intensifies.